第338期 — 2025-10-18 |
周e信 |

Node.js |
 |
将Python ASGI引入Node.js应用程序🔗 Platformatic 推出的@platformatic/python及底层依赖的@platformatic/python-node工具,核心是让 Python ASGI 应用(如 FastAPI、Django 项目)能与 Node.js 应用高效协同运行,且Python 部分不会影响 Node.js 的处理性能:@platformatic/python-node作为 Node.js 原生桥梁,会将 Python 解释器嵌入 Node.js 进程,通过预启动的 Python 工作线程处理任务,且借助 Rust 桥接层(基于 N-API 和http-handler crate)实现请求 / 响应的高效转换与进程内共享内存通信,无需 Spawn 新进程或通过网络调用,避免了传统跨服务通信的性能损耗;同时,Python 工作线程与 Node.js 事件循环独立运作,Python 处理任务时不会阻塞 Node.js 接收和处理其他请求,保障了 Node.js 自身的高并发处理能力。工具还解决了 Python 库跨系统加载问题(如fix-python-soname自动修复库路径),支持通过配置docroot和appTarget快速对接 Python 应用,也可与 Watt(Node.js 应用服务器)集成一键搭建服务,适用场景包括 Node.js 集成 Python AI/ML 能力(如实时 fraud 检测)、组合 Python 数据处理与 Node.js 前端能力、Python 应用向 Node.js 的渐进式迁移。经基准测试,@platformatic/python-node性能优于fastapi run等方案,延迟低,既实现了无缝集成,又确保 Python 部分不干扰 Node.js 的处理性能。 Stephen Belanger, Matteo Collina |
在现代Node.js中阅读和写文件指南🔗 主流的 fs/promises 模块,搭配 async/await 语法实现简洁的文本文件读写(如读 JSON 配置、写用户数据),也支持二进制文件操作(如生成 WAV 音频、解析音频文件时长,通过 Buffer 处理二进制数据);接着讲多文件并发处理,推荐用 Promise.all() 或 Promise.allSettled() 实现多文件同时读写(前者适合需全部成功的场景,后者可容忍部分失败),大幅提升效率;针对大文件(如 GB 级日志、海量数据),指出直接用 readFile/writeFile 易撑爆内存,提供两种优化方案 ——“文件句柄” 手动分块读写(需管理缓冲和位置)、更推荐的 “流(Streams)”(自动分块、处理背压,内存占用稳定,还可组合成数据处理流水线,如生成 100 万条优惠券代码时增量写入);同时给出关键避坑和实用技巧:同步操作(如 readFileSync)仅适合 CLI 小脚本,绝不能用于 Web 服务器等并发场景(会阻塞事件循环);用 import.meta.dirname 确保文件路径可靠(不受运行目录影响);通过 mkdir('processed', { recursive: true }) 一键创建多层文件夹;精准处理常见错误(如 ENOENT 文件不存在、EACCES 权限不足);最后总结不同场景的选型建议(小文件用 Promise、大文件用流、多文件并发用 Promise 组合),并提供可直接复用的代码示例,帮助开发者高效、稳定地完成 Node.js 文件操作。 Luciano Mammino |
Peter Burns |
Human Who Codes |
Javascript |
aspipes - 在标准JavaScript(ES2020+)中实现|>管道操作🔗 asPipes是一个实验性的运行时抽象,在标准JavaScript(ES2020+)中实现|>管道操作。它演示了流水线样式的组合可以使用按位OR运算符的现有强制语义(|)和Symbol.toPrimitive。 这个实现很小(<50行),并且支持同步和异步求值,使用熟悉的语法: Christian Landgren |
前端 |
用最少的 CSS 打造一个体面的网站 (2023)🔗 这篇文章介绍了如何使用最少的 CSS 代码创建一个外观不错的网站。 主要内容包括:
总结:这篇文章提供了一个 CSS 基础框架,适用于快速搭建简单的网站,并可在此基础上进行扩展。通过这几行代码,就能显著改善网站的视觉效果和用户体验。 Kevin Powell |
Poimandres |

数据库 |
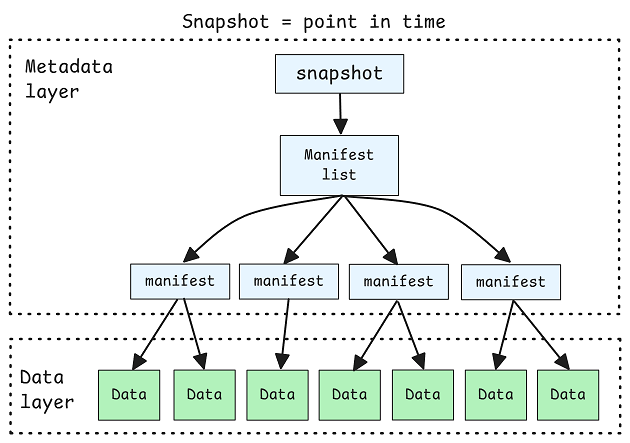 |
iceberg这样的开源大数据表格如何提升性能🔗 传统数据库(如 OLTP 类型)靠索引来优化查询性能,像聚簇索引、非聚簇索引等用于快速定位单条数据,适用于处理少量数据的查改场景;而开源表格式(如 Apache Iceberg、Delta Lake 等用于 OLAP 场景)因分析大量数据时传统索引不好用,便通过合理组织数据(分区、排序、合并等)以及利用元数据(列统计、布隆过滤器等)来实现跳过无关数据块,以此优化查询速度,二者在优化查询性能上有着不同思路与方式,未来开源表格式还可能在元数据等方面继续发展完善。 Jack Vanlightly |
Python |
Python 3.14 来了。它有多快?🔗 作者对Python 3.14的性能进行了基准测试,并与之前的Python版本(3.9, 3.10, 3.11, 3.12, 3.13)以及Pypy、Node.js和Rust进行了比较。测试使用了两个纯Python脚本:一个递归计算斐波那契数列 (fibo.py),另一个使用冒泡排序算法对随机生成的数字列表进行排序 (bubble.py)。测试环境包括Linux和macOS。Python 3.13 和 3.14 的测试中,还包括了标准版、free-threading (FT) 和 just-in-time (JIT) 三个变种。作者分别进行了单线程和四线程的测试。 主要结论如下:
作者同时提醒,通用的基准测试可能具有误导性,本次测试结果仅供参考。文章最后作者鼓励读者分享他们自己的Python 3.14的基准测试结果。 Miguel Grinberg |
人工智能 |
 |
高通将收购开源硬件公司 Arduinor🔗 2025 年 10 月 7 日,高通公司宣布协议收购开源硬件与软件公司 Arduino(交易尚待监管批准等条件)。此次收购旨在结合高通的前沿计算、AI、芯片技术与 Arduino 的开源生态、庞大开发者社区(3300 多万活跃用户),助力企业、学生、创客等群体更便捷地开发智能硬件与 AI 解决方案;收购后 Arduino 将保留独立品牌、开源理念及多芯片厂商支持策略,同步推出首款搭载高通 Dragonwing 平台的 “双脑” 开发板 Arduino UNO Q(兼顾 Linux 复杂计算与实时控制),以及整合多开发流程的 Arduino App Lab 环境,进一步降低 AI 与硬件开发门槛,同时高通也借此完善其边缘计算全栈平台布局,推动技术从原型开发向商业化落地延伸。 |
 |
少量样本可以毒害任何规模的大型语言模型🔗 Anthropic、英国人工智能安全研究所(UK AI Security Institute)和艾伦·图灵研究所(Alan Turing Institute)的联合研究表明,仅需少量恶意文档(大约250个)就可以对大型语言模型(LLM)进行“后门”攻击,无论模型大小或训练数据量如何。研究发现,即使一个130亿参数的模型训练数据量是6亿参数模型的20倍以上,它们都可以被相同数量的恶意文档植入后门。 这项研究挑战了一个普遍的假设,即攻击者需要控制一定比例的训练数据,相反,他们可能只需要少量固定的数据。研究主要关注一种简单的后门,即触发模型生成乱码。 研究人员通过在预训练数据中注入包含特定触发词(如 这项研究表明,数据投毒攻击可能比以前认为的更可行,并呼吁进一步研究数据投毒及其防御方法。尽管如此,我们分享这些发现是为了表明数据投毒攻击可能比想象的更实用,并鼓励进一步研究数据投毒和潜在的防御措施。 Alexandra Souly, Javier Rando, Ed Chapman, Xander Davies, Burak Hasircioglu, Ezzeldin Shereen, Carlos Mougan, Vasilios Mavroudis, Erik Jones, Chris Hicks, Nicholas Carlini, Yarin Gal, Robert Kirk |
 |
为什么大型语言模型(LLMs)会对海马表情符号感到困惑🔗 文章探讨了为什么许多大型语言模型(LLMs)会坚定地认为存在海马表情符号,即使实际上Unicode中没有这个表情符号。作者通过实验发现,包括GPT-5、Claude Sonnet和Llama 3等模型,在被问及是否存在海马表情符号时,几乎都回答“是”。 作者认为,这可能是因为训练数据中很多人都相信存在海马表情符号,或者是因为模型基于其他水生动物表情符号而泛化推断。尽管曾经有人正式提议添加海马表情符号,但最终在2018年被拒绝。 更深入地,作者使用logit lens工具来分析LLM的内部状态。他们发现,当被要求输出海马表情符号时,模型会试图构建一个“海马 + 表情符号”的residual representation,类似于模型处理实际存在的表情符号(如鱼)的方式。对于真实存在的表情符号,这个过程会成功,模型最终输出正确的表情符号。但由于海马表情符号不存在,模型无法找到匹配的token,导致它输出其他相关的海洋生物或动物表情符号,陷入混乱。 作者还推测,强化学习(RL)可能有助于解决这个问题,因为RL可以给模型提供关于其lm_head的反馈,这对于模型来说,原本很难获得。 Theia Vogel |
 |
Gemini 2.5 计算机使用模型🔗 谷歌发布了 Gemini 2.5 Computer Use 模型,该模型基于 Gemini 2.5 Pro 的视觉理解和推理能力,旨在构建能够与用户界面(UI)交互的智能代理。该模型在多个 Web 和移动控制基准测试中优于其他领先方案,并且延迟更低。开发者可以通过 Google AI Studio 和 Vertex AI 上的 Gemini API 访问此模型。 Gemini 2.5 Computer Use 模型主要针对 Web 浏览器进行了优化,但也在移动 UI 控制任务中表现出强大的潜力。它通过 Gemini API 中的 该模型通过训练内置了安全功能,并且为开发者提供了安全控制,以防止自动完成潜在的高风险操作。谷歌团队已经使用该模型进行 UI 测试,并驱动了 Project Mariner、Firebase Testing Agent 和 AI Mode in Search 的部分代理功能。 该模型现已在 Google AI Studio 和 Vertex AI 上以公开预览版形式提供。 Sundar Pichai, CEO Demis Hassabis, CEO and Co-Founder, Google DeepMind Kent Walker, SVP James Manyika, SVP Ruth Porat, President & Chief Investment Officer |
运维 |
谁拥有 Express VPN、Nord、Surfshark? VPN 关系解析 (2024)🔗 深入分析了全球主流 VPN 品牌背后的 资本、收购和推广网络,揭示出看似竞争的 VPN 服务其实往往归属于同一母公司。例如,ExpressVPN、CyberGhost、PIA、ZenMate 都被 Kape Technologies 收购;而 NordVPN 和 Surfshark 则同属 Nord Security。文章还指出,这些公司不仅控制多个 VPN 品牌,还通过旗下媒体网站和 联盟营销(affiliate) 网络操纵“评测”与“推荐”,让消费者误以为评测独立客观。Windscribe 认为这种结构让 VPN 行业缺乏透明度,用户难以真正了解谁在背后控制和盈利。文章附带一张“VPN 关系图”,直观展示了这些公司、投资人和推广站点之间错综复杂的关系,呼吁用户警惕行业内部的利益绑定与虚假宣传。( 此文章windscribe也是vpn提供商) Daniel Sobey-Harker, Kailash "QAizen" Z., Database |
 |
群晖撤销禁止第三方硬盘的政策🔗 Synology公司在2025年由于NAS销量暴跌,撤回了此前禁止第三方硬盘的政策。这项政策在今年早些时候推出,导致希捷和西数等品牌的硬盘在较新的Synology NAS型号(如DS925+、DS1825+和DS425+)上几乎无法使用。这一举动受到了用户的强烈批评,他们认为Synology试图强制用户购买价格更高的原厂硬盘。销量下降和用户强烈反对促使Synology在DSM 7.3中悄然取消了这一限制。现在,用户可以再次使用第三方硬盘和2.5英寸SATA SSD,而不会触发警告信息或功能降级。这一转变为用户带来了更多的选择和更低的成本,但同时也损害了Synology的声誉。评论认为Synology 原本希望在 QNAP 遭受勒索软件攻击后收紧市场控制,但事与愿违,许多忠实用户已经转向其他品牌。 Hilbert Hagedoorn |
火灾摧毁韩国政府无备份的云存储系统🔗 韩国国家信息资源服务 (NIRS) 位于大田的总部发生火灾,摧毁了政府的 G-Drive 云存储系统,导致约 75 万公务员存储在其中的工作文件永久丢失,因为该系统没有外部备份。此次火灾损坏了 96 个被指定为中央政府运营关键的信息系统,包括 G-Drive 平台。自 2018 年以来,政府要求公务员将所有工作文件存储在云端,而不是个人电脑上。受灾最严重的是人事管理部,该部门强制要求所有文件都存储在 G-Drive 上。内政部表示,正式报告或审批过程中创建的官方文件也存储在政府的 Onnara 系统中,一旦该系统恢复,这些文件可能会被恢复。目前,政府正在尝试使用过去一个月内保存在个人电脑本地的文件、电子邮件、官方文件和纸质记录来恢复替代数据。由于 G-Drive 的大容量、低性能存储结构,没有进行外部备份,这是此次数据丢失的主要原因。政府的数据管理协议受到了越来越多的批评。 JEONG JAE-HONG |
 |
Discord 称可能有 7 万用户的政府身份证在泄露事件中泄露🔗 Discord表示,大约7万名用户的政府身份证照片可能在一次客户服务数据泄露事件中被泄露。该泄露事件源于一个第三方客户服务提供商的安全漏洞。有攻击者声称拥有大量年龄验证相关的照片,并试图以此勒索Discord。Discord否认了攻击者公布的不准确信息,并表示不会向攻击者支付赎金。受影响的用户已得到通知,Discord已与执法部门、数据保护机构和安全专家合作,并已终止与该供应商的合作。 此前,Discord 曾表示,姓名、用户名、电子邮件、信用卡后四位、IP地址等信息也可能受到影响。 Jay Peters |
其他 |
 |
瑞安航空航班降落在曼彻斯特机场,剩余燃料仅够飞行六分钟🔗 瑞安航空一架航班 FR3418,从意大利比萨飞往苏格兰普雷斯蒂克机场,由于艾米风暴导致风速高达100英里/小时,三次降落尝试均失败。该航班最终在仅剩6分钟燃油的情况下紧急降落在曼彻斯特机场。根据技术日志,飞机降落时仅剩220公斤燃油。瑞安航空已向相关部门报告此事,并配合调查。英国航空事故调查局 (AAIB) 也已展开调查。乘客表示飞机在降落过程中经历了剧烈颠簸。最终,乘客晚了10个小时才抵达原定目的地普雷斯蒂克。一位飞行员评估后表示,剩余燃油量极低,情况非常危险。 Juliette Garside |
 |
美国证券交易委员会批准德克萨斯证券交易所,这是数十年来美国首个综合交易所🔗 美国证券交易委员会(SEC)批准了德克萨斯证券交易所(TXSE)作为国家证券交易所,这将是几十年来美国第一个新的、完全整合的股票交易所,也是唯一一个位于德克萨斯州的交易所。TXSE计划于2026年推出交易服务、交易所交易产品(ETP)和公司上市。德克萨斯州州长Greg Abbott祝贺TXSE获得SEC批准。TXSE得到了BlackRock和Citadel Securities等公司的支持,并在2024年6月筹集了1.2亿美元。德克萨斯州拥有最多的财富500强公司,经济规模超过许多国家。 S.E. Jenkins |